Spark Execution Modes

In this post, we will discuss the different execution modes available in Apache Spark. Apache Spark provides three execution modes to run Spark applications. These execution modes are: Cluster mode, Client mode, and Local mode. Each of these modes has its own use case and is suitable for different scenarios.
To have an understand of the execution mode, we will need to re-visit the high-level components of a Spark application, those are:
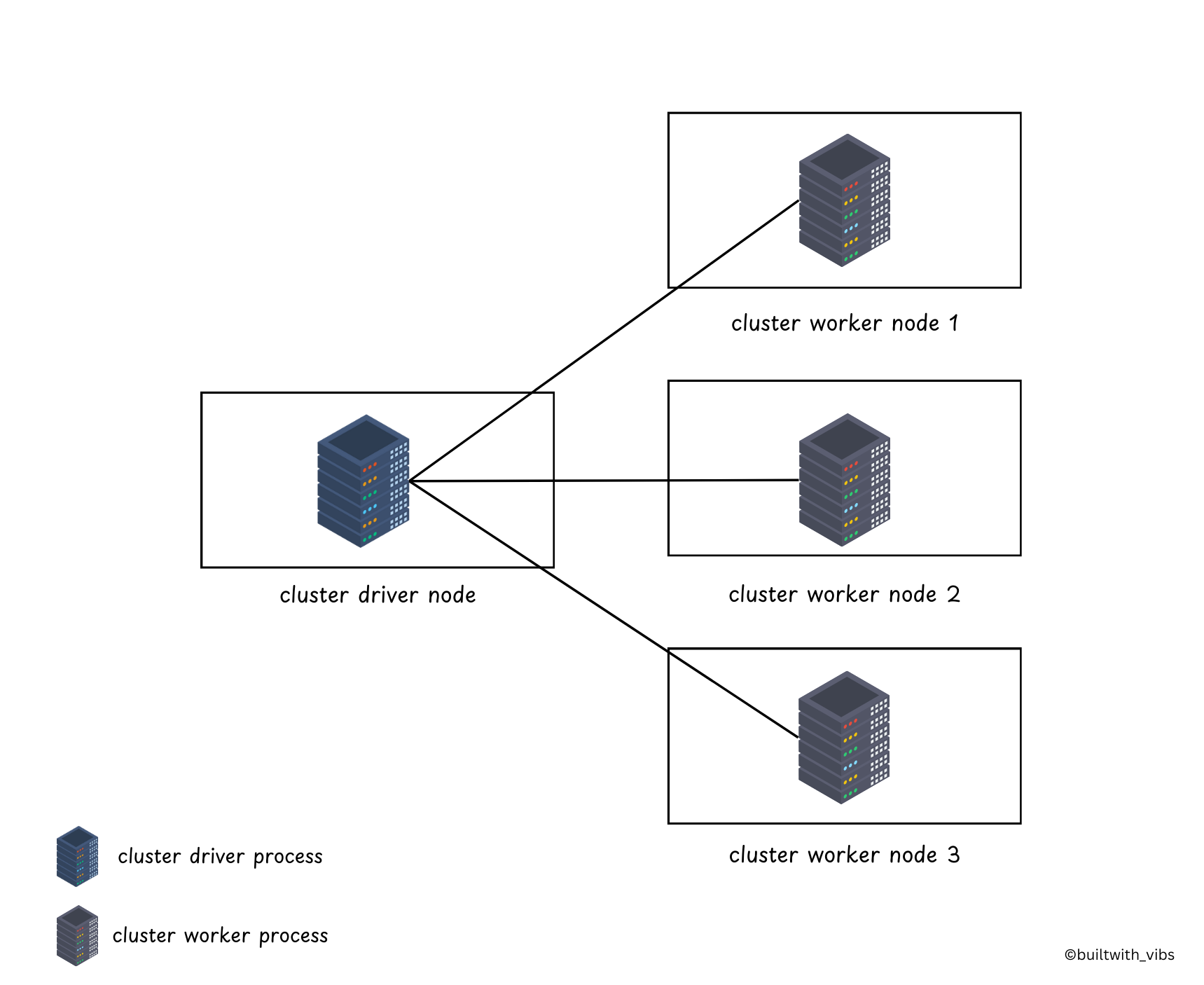
- The Spark Driver:
- Driver is the controller of the execution of the spark application, it maintains the state of the spark cluster (the state and tasks of the executors).
- It will interact with the cluster manager to allocate resources for the executors and schedule tasks on the executors.
- The driver is just a process on the physical machine, which is responsible for maintaining the state of the application running on the cluster.
- The Spark Executors:
- Executors are the processes that run the actual tasks of the spark application, assigned by the driver.
- The main responsibility of the executor is to
- take the tasks from the driver
- run the tasks
- report back the status of the tasks to the driver and results.
- Cluster Manager:
- The cluster manager is responsible for maintaining a cluster of machines that will run your Spark Application(s).
- Somewhat confusingly, a cluster manager has its own "driver" (sometimes referred to as master) and "worker" abstractions.
- The key difference is that these abstractions are tied to physical machines rather than processes, as they are in Spark.
Analogy
Running a Spark application is like managing a busy restaurant where each component plays a distinct role to ensure everything runs smoothly and efficiently:
- Spark Driver (Head Chef): The head chef manages the kitchen, assigns tasks to the cooks (executors), and makes sure every dish is prepared correctly.
- Spark Executors (Cooks): The cooks prepare the dishes following the head chef’s instructions and report back when each dish is ready.
- Cluster Manager (Restaurant Manager): The restaurant manager ensures the kitchen has enough staff, ingredients, and equipment to run smoothly, handling multiple orders at once.
Execution Modes
An execution mode gives you the power to determine where the aforementioned resources are physically located when you go to run your application.
Cluster Mode
- The user submits a JAR, Python script to the cluster manager.
- The cluster manager launches both the driver and executors on worker nodes within the cluster.
- The driver process runs on one worker node, while executors run on other worker nodes.
- The cluster manager manages and monitors all Spark application processes.

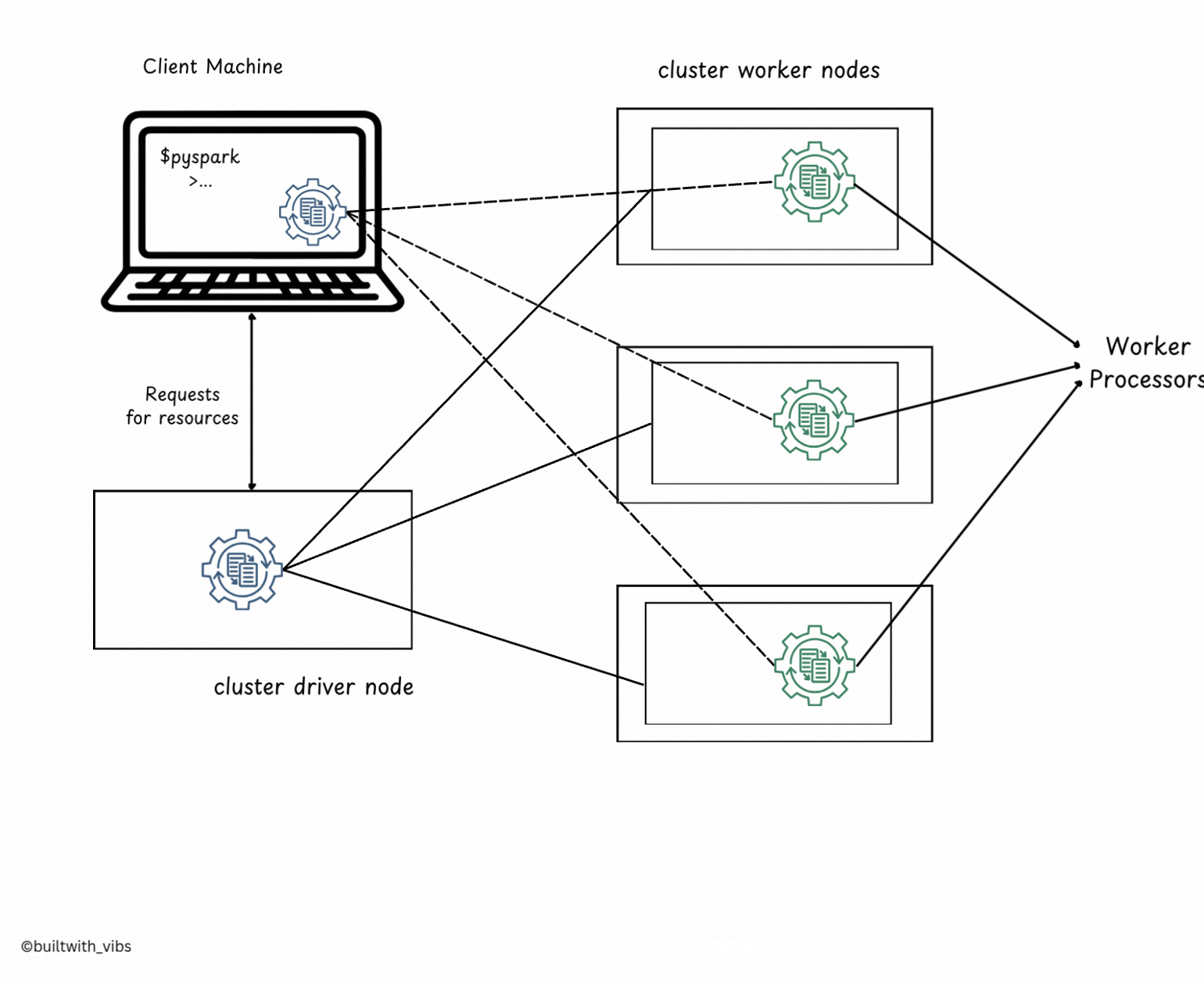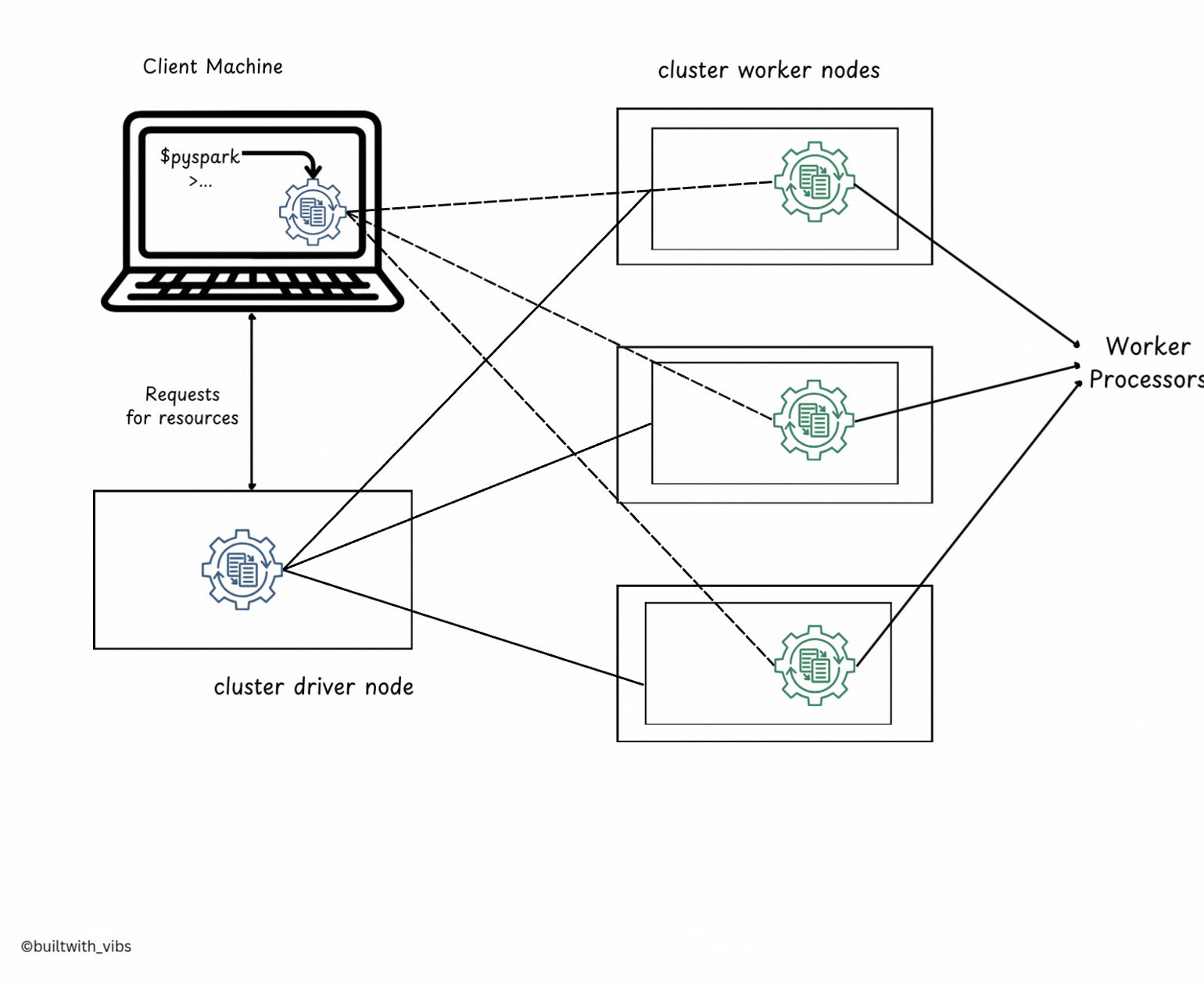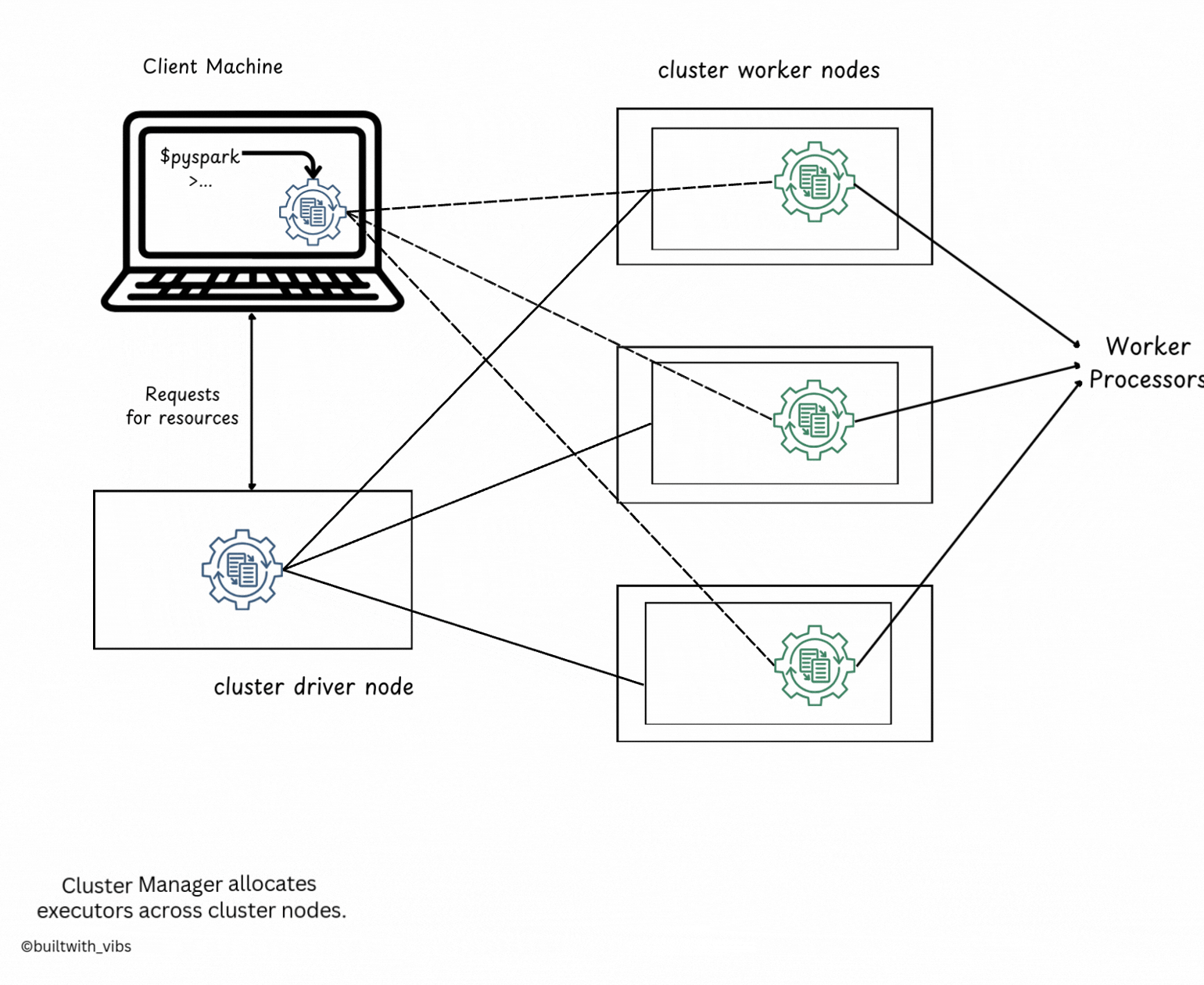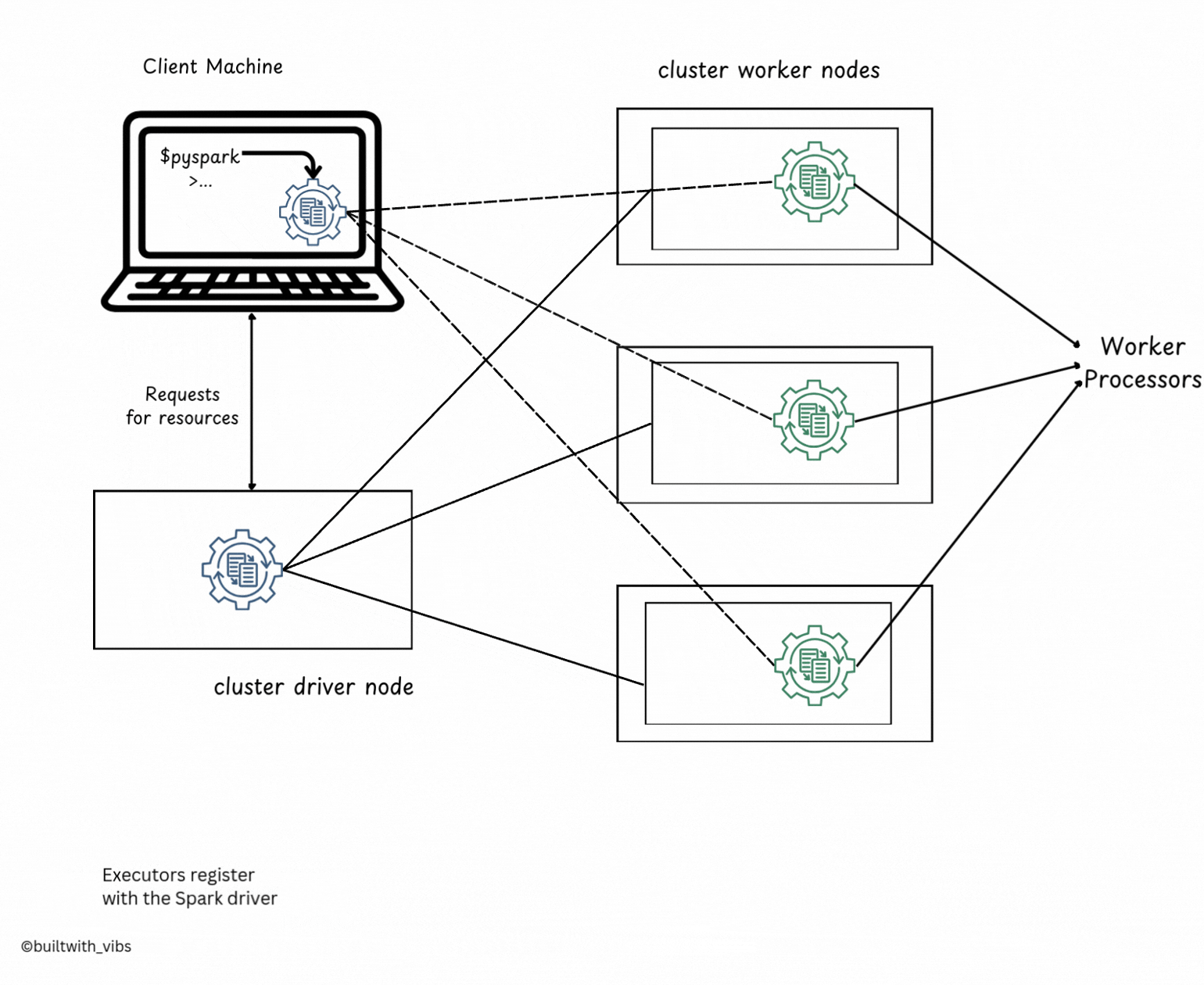
Client Mode
- Client Mode is similar to Cluster Mode, but the Spark Driver runs on the client machine (the machine that submits the application).
- The client machine is responsible for managing the driver process.
- The cluster manager handles the executor processes, which run on worker nodes in the cluster.
- In Client Mode, the application is submitted from a machine outside the cluster, often called a gateway machine or edge node.
- The driver stays on the client machine, while executors run inside the cluster on worker nodes.
Local Mode
- Local Mode runs the entire Spark application on a single machine.
- It achieves parallelism using threads on the same machine, not multiple worker nodes.
- Used for learning Spark, testing applications, and iterative development.
- No cluster manager is required; Spark manages everything locally.
- Ideal for small datasets and quick experiments but not suitable for production or large-scale jobs.
Conclusion
| Client Mode | Cluster Mode | |
|---|---|---|
| Best for | Interactive use (development, debugging) | Production jobs, large-scale deployments |
| Latency | Lower latency for small tasks | Slightly higher due to internal resource allocation |
| Example Use Case | Testing and interactive Spark shells | Scheduled batch jobs or long-running Spark applications |
| Advantages | Easier to debug and monitor from client machine | More reliable and scalable for production workloads |
| Disadvantages | Unreliable for long-running tasks | More setup needed, harder to debug directly |
I hope this blog helped you understand the different execution modes. To learn more about the Spark application architecture, you will find it here. If you are interested in reading more about Spark, check out the other posts in this series. If you have any questions or feedback, feel free to reach out to me on